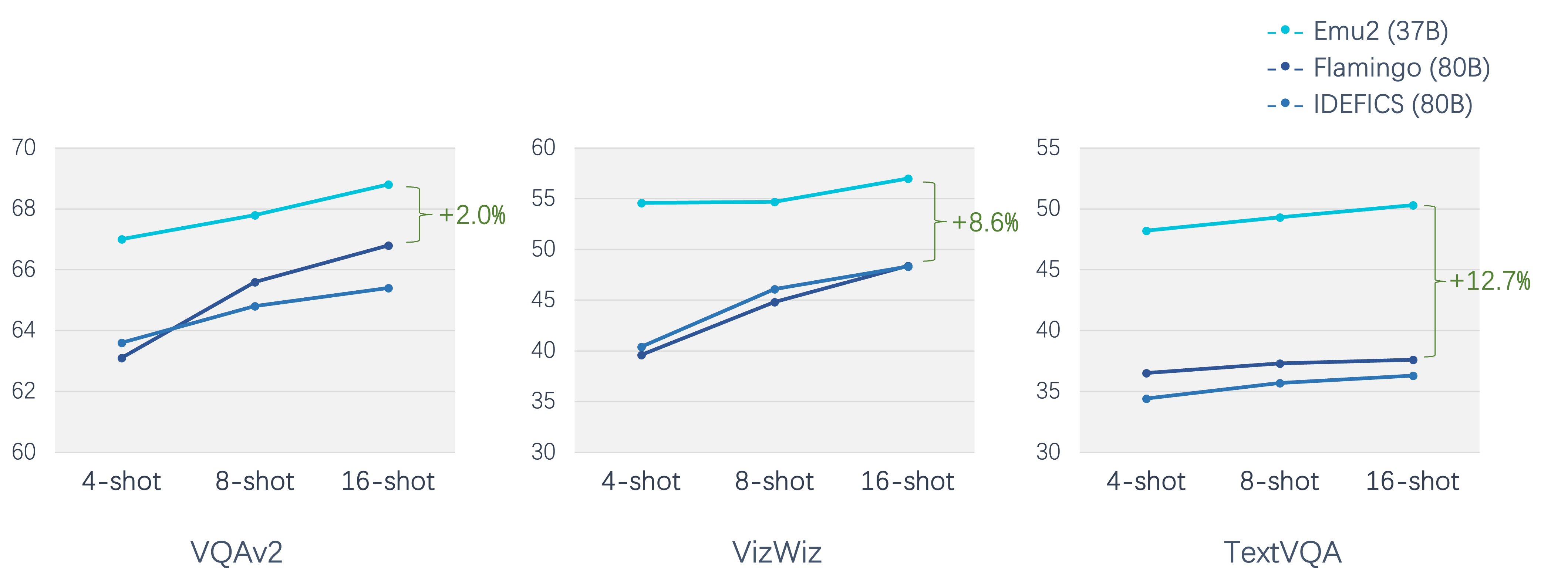
A strong multimodal few-shot learner
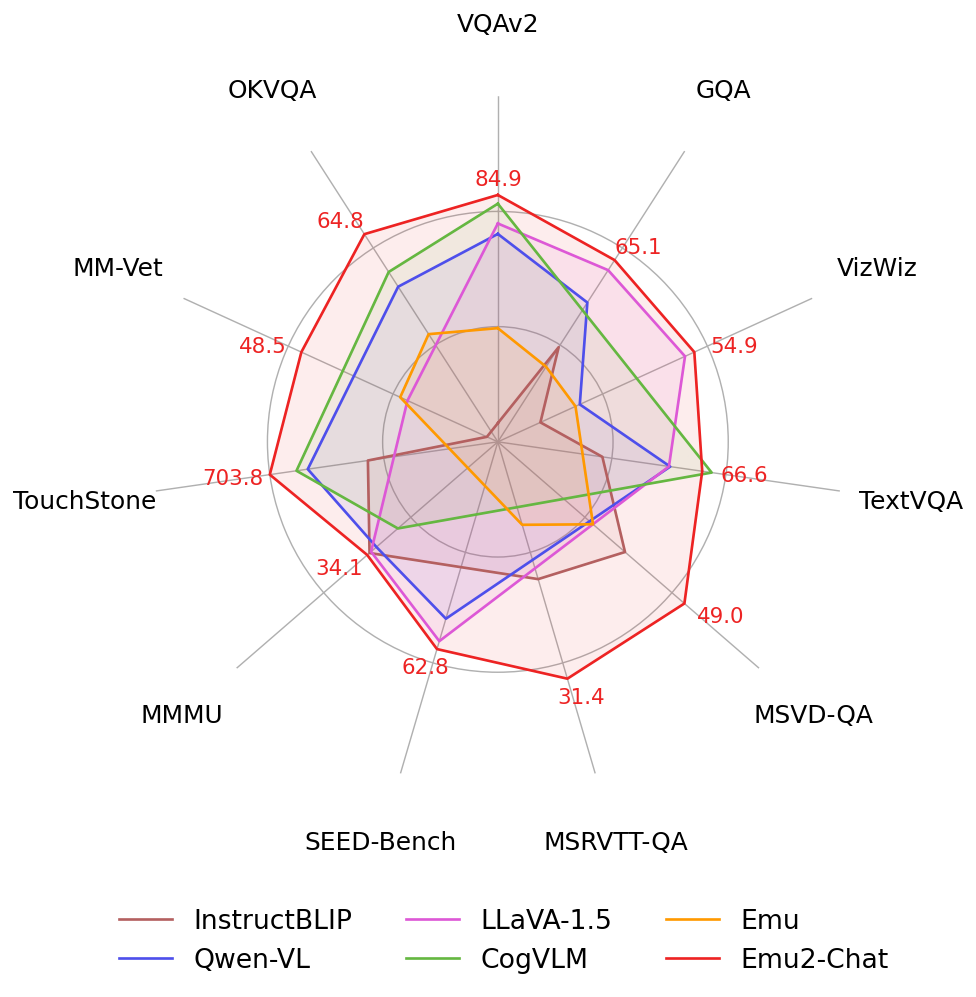
An impressive multimodal generalist
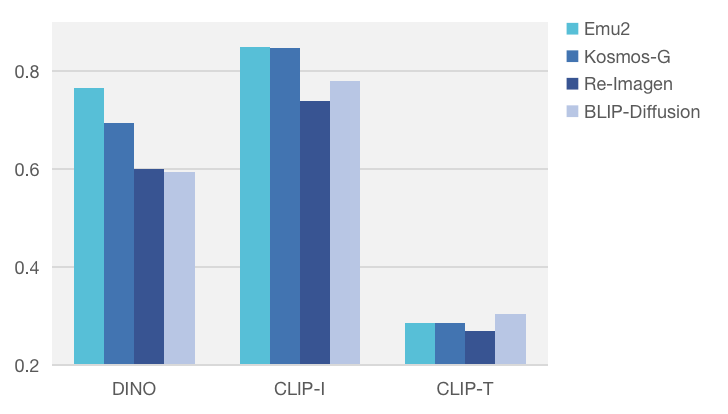
A skilled painter
Zero-shot subject-driven generation
Multimodal in-context learning
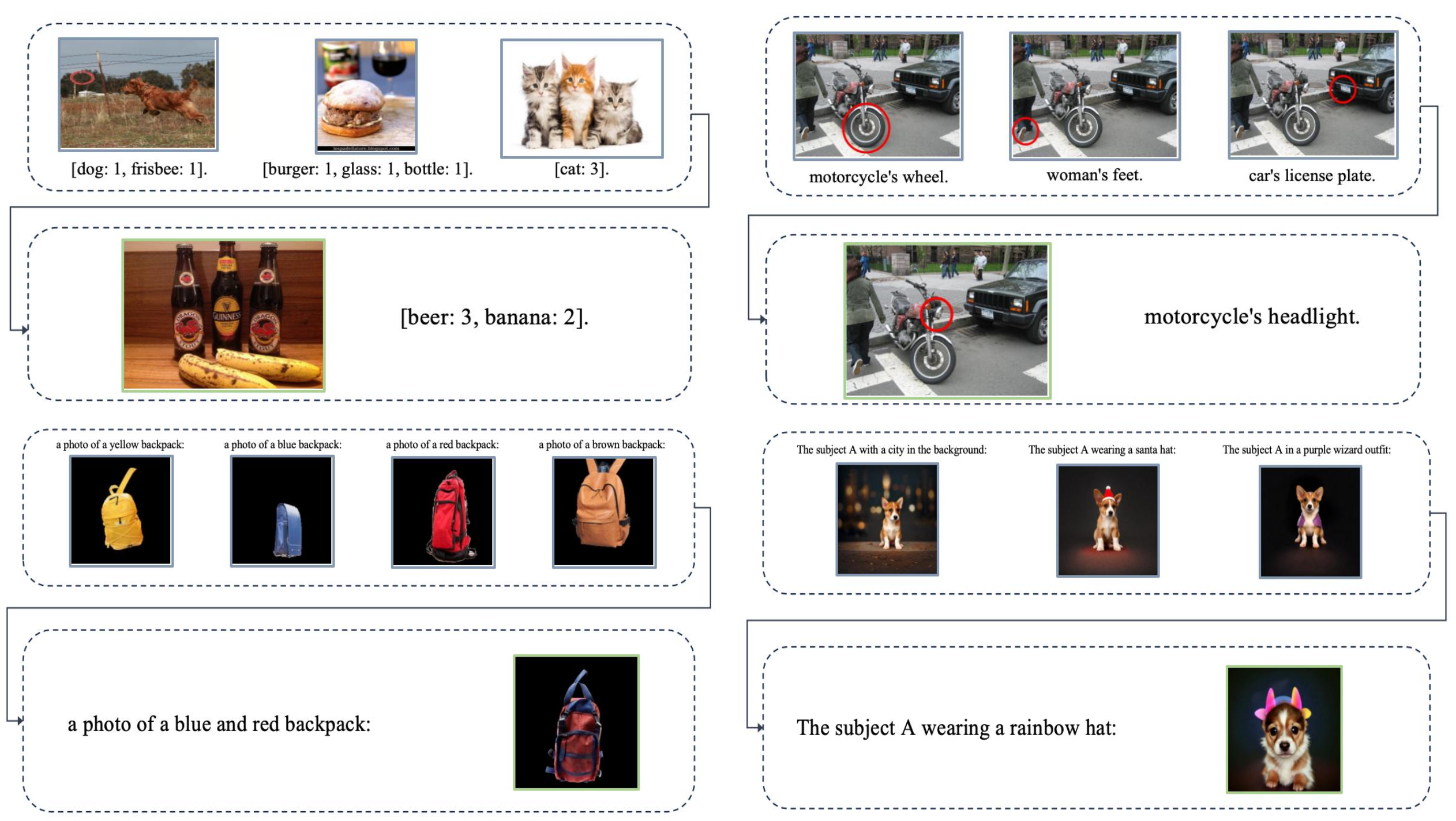
Strong multimodal understanding




Generate image from any prompt sequence



Generate video from any prompt sequence

Generate image from any prompt sequence
Generate video from any prompt sequence
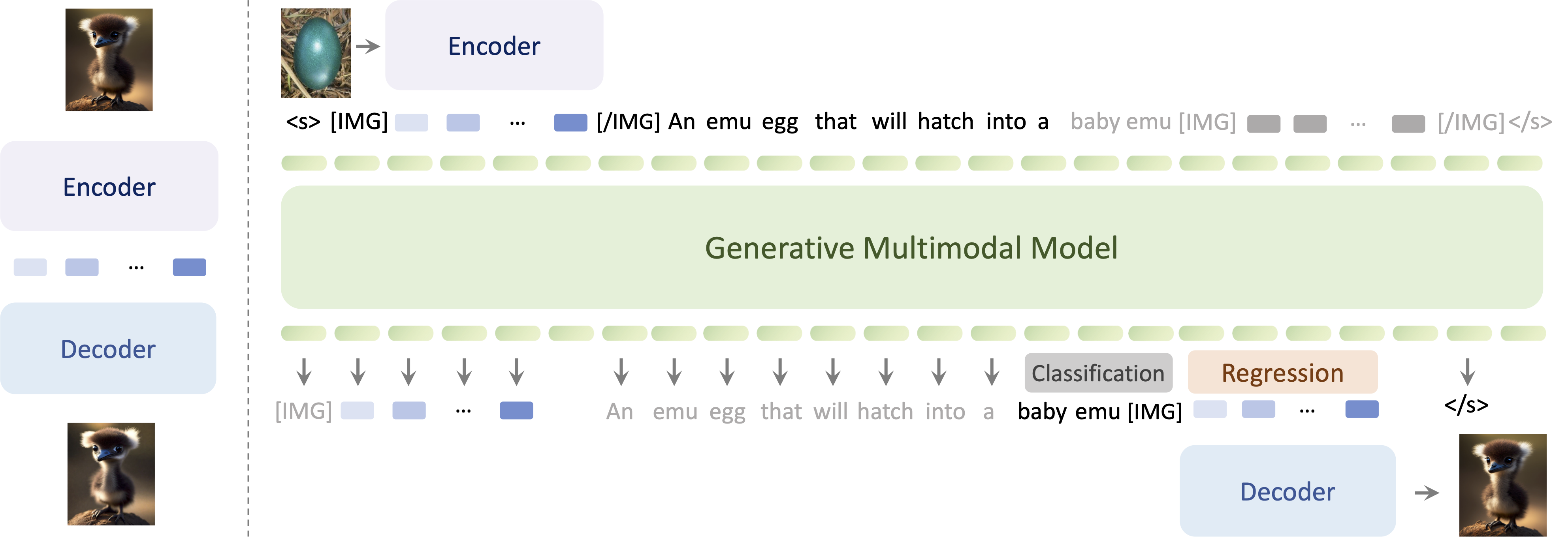
Method
Emu2 learns with a predict-the-next-element objective in multimodality. Each image in the multimodal sequence is tokenized into embeddings via a visual encoder, and then interleaved with text tokens for autoregressive modeling. The regressed visual embeddings will be decoded into an image or a video by a visual decoder. Compared to Emu1, Emu2 embraces a simpler framework, better visual decoder, and scales up to 37 billion parameters.
BibTeX
@article{Emu2,
title={Generative Multimodal Models are In-Context Learners},
author={Quan Sun and Yufeng Cui and Xiaosong Zhang and Fan Zhang and Qiying Yu and Zhengxiong Luo and Yueze Wang and Yongming Rao and Jingjing Liu and Tiejun Huang and Xinlong Wang},
publisher={arXiv preprint arXiv:2312.13286},
year={2023}
}